
最近Pythonにはまっています。
ついでに機械学習の勉強にもはまっています。
こりゃあ建築批評空間を可視化するしかあるまい。
公開されている建築批評といえば「『10+1』データベース」ですね。
なんとなく見た感じ、アドレスは
![]()
こんな感じになってるので、適当に番号を増やしてったところ、どうやら1549まであるみたい。
というわけで、全ページを次のシェルスクリプトで取得します
#
var1=http://db.10plus1.jp/backnumber/article/articleid/
var2=.html
for ((i=1;i<1550;i++))
do wget -O $i$var2 $var1$i/
done;この1549の中にも歯抜けになってる番号が100ありました。
それで、記事によっては

こんな具合に公開されてないものもあります。全1449記事のうち、公開数:721、未公開数:728 でした。約半数が公開されているようです。
さて、いろいろやってみたいことはあるのですが、まずは簡単に記事同士の関係をみてみようと考えました。
記事を見てみると、各記事の右側には著者名が並び、その記事の掲載号情報があり、以降は文中で言及されるキーワードが解説されていることが分かります。

この著者としての登場回数とか、誰の記事で誰がよく言及されるとかを調べると面白そうです。というわけで、htmlソースから該当部分をPythonでBeautifulSoupを使って抜き出し、pymongoを使ってmongodbにブッ込みました。
なんでmongodbかというと、あとでheroku上でなんか作ろうかなとか思ってるからです。今回はやりませんが。

当該情報はannotationクラスのdiv内にあるので、
# -*- coding: utf-8 -*-
import sys
import codecs
import re
import pymongo
from BeautifulSoup import BeautifulSoup
sys.stdin = codecs.getreader('utf-8')(sys.stdin)
sys.stdout = codecs.getwriter('utf-8')(sys.stdout)
R_END_AUTHOR = re.compile(r'『10+1』')
def getNavigableStrings(soup):
if isinstance(soup, BeautifulSoup.NavigableString):
if type(soup) not in (BeautifulSoup.Comment,
BeautifulSoup.Declaration) and soup.strip():
yield soup
elif soup.name not in ('script', 'style'):
for c in soup.contents:
for g in getNavigableStrings(c):
yield g
def parseAuthorAndKeyword(num, col):
filename = 'html/'+str(num)+'.html'
f = open(filename, 'r')
data1 = f.read()
f.close()
soup = BeautifulSoup(data1)
enc = soup.originalEncoding
# print "Encoding : %s" % enc
# print unicode(soup.prettify(), enc)
author = []
keyword = []
authorFlag = True
# author, keyword
for table in soup('div', {'class':'annotation'}):
# get content name
name = table.findAll('h5')[0].next.next.string.encode('utf-8')
if authorFlag:
if R_END_AUTHOR.match(name):
authorFlag = False
continue
splitted = name.split('(')
author.append(splitted[0])
else:
splitted = name.split('(')
keyword.append(splitted[0])
# article
# locked
articleFlag = -1
# limited
for article in soup('div', {'class':'articleLimitedUnitBox'}):
articleFlag = 0
# published
for article in soup('div', {'class':'articleUnitBox'}):
articleFlag = 1
doc = { 'author': author, 'keyword': keyword, \
'number': num, 'published': articleFlag }
col.insert(doc)
def main():
conn = pymongo.Connection()
db = conn['10+1']
col = db['authors']
for i in range(1, 1550):
print i
parseAuthorAndKeyword(i, col)
conn.disconnect()
if __name__ == '__main__':
main()こんな具合で抜き出します。
関数parseAuthorAndKeywordで抜き出しを行なっています。BeautifulSoupで当該タグまで下り、table.findAll(‘h5’)[0].next.next.string.encode(‘utf-8’)で抜き出しています。名前にリンクが付いている人と付いてない人とがいたので、どっちでもいけるようちょっと汚くなっています。
それと、だいたい名前は「磯崎新(イソザキ・アラタ)」みたいな形になってて、カッコの中はいらないので、splitted = name.split(‘(’)でカッコの始まりで分割し、splitted[0]で前半部分だけ保存してます。
pymongoについてはググれば分かります。
次は、著者として登場するすべての人物について、その人の記事中であるキーワードが右に解説されていたら著者→キーワードとなる辺を持つようなグラフ(隣接辺リスト)をつくります。辺の重みはその記事数です。
さて、いよいよ可視化です。可視化にはcytoscapeを使おうと思ってやってみたんですが、web上で見るのに不便だなと思ったので、もうちょっとイケてるGephiを使って、web上での閲覧はgexf-jsという素晴らしいライブラリを使わせてもらうことにしました。
cytoscapeで読み込む隣接辺リストはsource, target, weightを一行とするcsvファイルでいいのですが(この辺は井庭崇先生のブログがわかりやすい)、Gephiの場合はsource, targetを一行とするcsvファイルです。
重みについてはすべての辺の重みを1として、同じsource, targetの辺の数がその辺の重みとなります。
# -*- coding: utf-8 -*-
import sys
import codecs
import pymongo
sys.stdin = codecs.getreader('utf-8')(sys.stdin)
sys.stdout = codecs.getwriter('utf-8')(sys.stdout)
convert_tuples = [
(u'\u00a6',u'\u007c'),#broken bar=>vertical bar
(u'\u2014',u'\u2015'),#horizontal bar=>em dash
(u'\u2225',u'\u2016'),#parallel to=>double vertical line
(u'\uff0d',u'\u2212'),#minus sign=>fullwidth hyphen minus
(u'\uff5e',u'\u301c'),#fullwidth tilde=>wave dash
(u'\uffe0',u'\u00a2'),#fullwidth cent sign=>cent sign
(u'\uffe1',u'\u00a3'),#fullwidth pound sign=>pound sign
(u'\uffe2',u'\u00ac'),#fullwidth not sign=>not sign
]
def unsafe2safe(string):
for unsafe, safe in convert_tuples:
string = string.replace(unsafe, safe)
return string
def frequencyOfItemsInKey(col, key):
"""
return dic of all items and its frequency appeared in key.
{key1:val1, key2:val2, ...}
"""
dic = {}
# for all documents
for doc in col.find():
# for each key
for i in range(len(doc[key])):
buff = {doc[key][i]: \
col.find({key: doc[key][i]}).count()};
dic.update(buff)
return dic
def frequencyOfSecondInFirst(col, firstKey, first, secondKey):
"""
return frequency of keyword in author's text.
{first: {second1:val1, second2:val1, ...}}
"""
buff = {}
# for all documents of which firstKey is first
for doc in col.find({firstKey:first}):
# for each secondKey
for i in range(len(doc[secondKey])):
buff2 = {doc[secondKey][i]: \
col.find({firstKey: first, \
secondKey: doc[secondKey][i]}).count()
}
buff.update(buff2)
dic = {first: buff}
return dic
def writeDicRankToTSV(dic, filename):
"""write dic to TSV as a ranking of the value."""
f = codecs.open(filename, 'w', 'utf-8')
for key, val in sorted(dic.items(), key=lambda x:x[1], reverse=True):
if key == '\n': continue
buff = str(key)+'\t'+str(val)+'\n'
f.write(buff)
f.close()
def makeASetOfKey(col, key):
"""make a key set."""
keys = []
for doc in col.find():
for i in range(len(doc[key])):
keys.append(doc[key][i])
keys = set(keys)
return keys
def writeNetworkAsEdgeList(network, filename):
"""for cytoscape."""
f = codecs.open(filename, 'w', 'shift-jis')
for person in network.keys():
for keyword in network[person].keys():
buff = person+','+ \
keyword+','+str(network[person][keyword])+'\n'
buff = unsafe2safe(buff)
f.write(buff)
f.close()
def writeNetworkAsEdgeListGephi(network, filename):
"""for gephi."""
f = codecs.open(filename, 'w', 'utf-8')
for person in network.keys():
for keyword in network[person].keys():
# repeat for edge weight
for i in range(network[person][keyword]):
buff = person+','+keyword+'\n'
f.write(buff)
f.close()
def main():
# connect with mongodb
conn = pymongo.Connection()
db = conn['10+1']
col = db['authors']
# make ranking of authors and keywords
dic = frequencyOfItemsInKey(col, 'author')
writeDicRankToTSV(dic, 'authorRank.txt')
dic = frequencyOfItemsInKey(col, 'keyword')
writeDicRankToTSV(dic, 'keywordRank.txt')
# make a reference network
authors = makeASetOfKey(col, 'author')
dic = {}
# for all authors
for person in authors:
buff = frequencyOfSecondInFirst(col, 'author', person, 'keyword')
dic.update(buff)
writeNetworkAsEdgeList(dic, 'referenceNetwork.csv')
writeNetworkAsEdgeListGephi(dic, 'referenceNetworkForGephi.csv')
# basic information
numPages = col.count()
numLocked = col.find({'published': -1}).count()
print u'全記事数', numPages - numLocked
print u'未公開記事数', col.find({'published': 0}).count()
print u'公開済み記事数', col.find({'published': 1}).count()
# disconnect with mongodb
conn.disconnect()
if __name__ == '__main__':
main()ちなみにcytoscapeはshift-jisでないといけないので、この記事のやり方でutf-8から変換しています。Gephiはutf-8でいける。
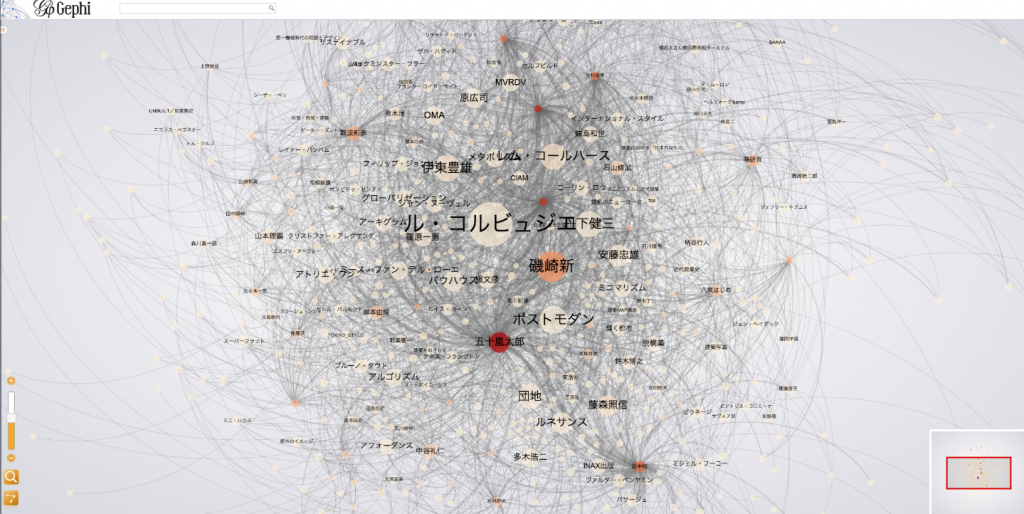
さて、まずはそのまんま可視化した場合(画像クリックで開きます)。

- 言及されてる回数が多いほどノードが大きく、
- 言及数が多い人(多くのキーワードに言及している人)ほど赤く、
- 文字の大きさは両方を合わせた数が多いほど大きくなっています
あとで言いますが言及数は記事数が多いほど多いですね当然。
では次は次数が1(言及、被言及合わせて1回だけ)のノードを排除し、その上で辺の重みが2以下の辺を排除したグラフです。いわばテンプラスワン批評空間における特権階級たちです。

では記事投稿数ランキング上位21人(同率がいるため)です。
五十嵐太郎 72
田中純 55
日埜直彦 47
八束はじめ 38
塚本由晴 34
上野俊哉 32
中谷礼仁 29
篠儀直子 29
内田隆三 29
今村創平 27
吉村靖孝 26
南泰裕 23
石川初 19
磯崎新 19
椹木野衣 18
多木浩二 17
大島哲蔵 16
今井公太郎 16
毛利嘉孝 15
西沢大良 14
貝島桃代 14
椹木野衣さん多いんですね。意外でした。それでは被言及ランキング上位21人です。
ル・コルビュジエ 114
ポストモダン 92
磯崎新 80
レム・コールハース 64
伊東豊雄 54
丹下健三 50
INAX出版 48
ヴァルター・ベンヤミン 47
ルネサンス 47
パサージュ 35
安藤忠雄 35
藤森照信 35
バウハウス 34
原広司 33
メタボリズム 32
現代住宅研究 31
アルゴリズム 30
アーキグラム 29
ミース・ファン・デル・ローエ 28
コーリン・ロウ 28
篠原一男 28
コルビュジェ先生はさすがですね。テンプラスワンがポストモダンの建築批評誌であることがよく分かります。INAX出版はやりよるなという感じですかね。
これからはもうちょっと面白い特徴を見つけてみようと思います。
あと本文抽出もできるのでMeCabを使ってなんかしてみようと思います。まずは多分ナイーブベイズを試すと思われます。
大澤と申します。 gephiとgexf.jsを用いたネットワーク表示についてご教示いただきたく、コメント欄を使わせて頂きます。 gephiに代表されるプログラムについては全くの素人のため、どのようにgexf.jsを使うのかが分からず困っております。gexf-jsのサイトでの“How to Use”では既述が簡潔過ぎてその手順が理解できません。ご教示願えたら幸いです。
(gephiについては、インストール、デモファイルで利用方法までは理解できております)
本日午前中に質問をさせて頂いた者です。 IEではなくFirefoxで試しましたら、表示することが出来ました。原因は不明ですが、何とかなりそうですので、午前中のお願いは取り消させて頂きます。
(gexf.jsを使うに当たっては、貴HPがとても参考となりました。改めて、お礼を申し上げます)
大澤さま
ご質問ありがとうございます。もう解決されたようなので蛇足かもしれませんが、おそらくそれはドメイン外のファイルをロードできないようになっているのだと思います。
IEのほか、chromeでも同様の結果になるはずです。別ドメイン、私のブログでしたら”sekailab.com”以外の場所をソース中で読み込めないようになっているということです。
私はWEBサーバ上、つまり”sekailab.com”内で動かしているので問題はないのですが、ローカルでやるとこの問題に引っかかるようです。
http://tomio2480.hatenablog.com/entry/20120922/1348262110
をご参照ください。
gephi関連については需要がありそうなので使い方などまとめようと思ってはいるのですがいつになることやら。。。
とりあえず大澤さまの件が上手くいくよう願っております。
オーナー様、
コメントを頂戴しながら、お礼を申し上げるのが大変に遅くなってしまいました。失礼の段、お許し下さいませ。
少し試した結果を記しますので、再度ご教示いただけたら幸いです。
chromeで “–allow-file-access-from-files”を起動オプションに付けましたら、可能となりましたが、IEでは相変わらず不可のままです。
この “–allow-file-access-from-files”を検索しますと、”ローカル内でのファイルアクセスを許可する”と出て来ます。
それではと、ローカル内で全て完結する簡単なファイル参照プログラムを(html)で作成し、試しましたら、firefox,chrome(–allow-file…なし),IEとも参照可能でした。(この確認に時間を取られました)
このことから、gexfjsのソース自体もローカルに落としていますので、chrome(–allow-…なし),IEでも開けるのではと思ってしまいますが、実際にはNGです。
この理解の間違っているところを、ご教示願えませんでしょうか?
#webシステムについて理解不足で恐縮です。
もう一つ、gexf.jsに関わるところでご存知でしたらお教え頂ければと思います。
ノードに特定ファイル&特定場所へのリンクを張りたいのですが、ファイルまではリンク可能なのですが、特定場所へのリンクが出来ずに苦しんでいます。
(gexfjs.js:function replaceURLWithHyperlinks
の一部を変更)
ノードで指定するファイルは、AcrobatX上でリンク先場所を指定したpdfです。上述のhtmlで作成したファイルにて、特定ファイル#特定場所へのリンクまでは確認出来ております。
以上、宜しくお願い致します。
度々で申し訳ございません。
昨日お伺いした内容の後半(ファイルの特定箇所にリンクを張りたい)につきましては、下記の手順で解決いたしましたので、ご連絡をさせていただきます。
gexfjs.jsのfunction replaceURLWithHyperlinksにおいて、
var _urlExp = …
の右辺正規表現最後尾で、
/[-A-Z…] を [-A-Z…]に修正
(これにより、場所指定の#以下が拾える)
お騒がせいたしました。