

自然言語処理はBERTやGPT-2など話題に事欠きませんが、こういうのってシングルGPUとかで学習できんのかってなるわけです。どちらもtransformerを使ってるわけで、transformerこそがエポックでCNNがlstmよりも良いじゃんってなったのがtransformerのおかげなのです。
そしてみんな大好きTensor2Tensor、別名「誰でも最新ディープモデルライブラリ」ではLanguage Modeling、seq2seq、Sentiment Analysisとかでtransformerが使えるんです。マジかよ
ということで試してみます。3年以上前にlstmで会話ボットを作ってみたんですがそれよりも遥かに良いものができました(当然ですが)。

Contents
チャットボットのタスク
チャットボットと言われるもののタスクはNLP的に分解すると以下のようなものかと思います:
- 質問回答: 問いかけに対して答える
- 文章生成: なんらかの話題に関して文章を生成する
3年前に作ったモデルでは、質問回答に対してLanguage Modelingを使っていました。質問文に続く文を生成するというやり方ですね。
今回はseq2seqを使って質問→回答のペアを学習させてみましょう。機械翻訳と同じやり方ですね。
データセット
対話破綻検出チャレンジの雑談対話コーパスから、対話がうまくいってるっぽいもの + SNSから収集した独自データを使います。
合計3万ぐらいの質問・回答ペアです。
しかしRTX 2018Ti(11GB)で学習させるには10万ペアぐらいはほしいので、下記の方法でデータを増やしてみます。
会話データセットを増やす
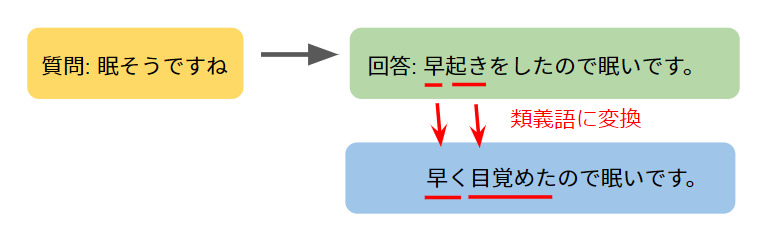
日常会話を振り返ってみましょう。同じ質問に対しても類義語を使った何通りもの回答方法が可能です。例えば、「眠そうですね」という問いかけに対して「早起きをしたので眠いです。」、「早く目覚めたので眠いです。」という回答はどちらも自然です。つまり、文中の単語のいくつかを類義語に変換しても会話としては自然な場合が多いと予想できます。
ということで質問または回答をSentence Pieceで単語分割し、漢字やカタカナを含むものはword2vecで類義語に変換します。元のペア、質問を変換したペア、回答を変換したペアでデータセットはなんと3倍になります。しかもなんか類義語を含む似たような文を学習させることでrobustnessが向上しそうな感じがしますね(個人の感想です)。
学習
Tensor2Tensorをそのまま使っても良いのですが、transformerは結構ハイパーパラメータの選択が難しいです。モデルが複雑すぎると思ったよりlossが下がってくれません。
そこでOptunaです。OptunaをTensor2Tensorに組み込んだものを以前作ったのでこれを使って学習させます。

- learning_rate_constant = 0.1
- learning_rate_schedule = “constant*linear_warmup*rsqrt_decay”
- learning_rate_warmup_steps = 16000
- num_hidden_layers = 3
- hidden_size = 256
- attention_dropout = 0.4139955949320395
- hparams.relu_dropout = 0.4361243501997365
とかにすると良い感じに学習してくれました。
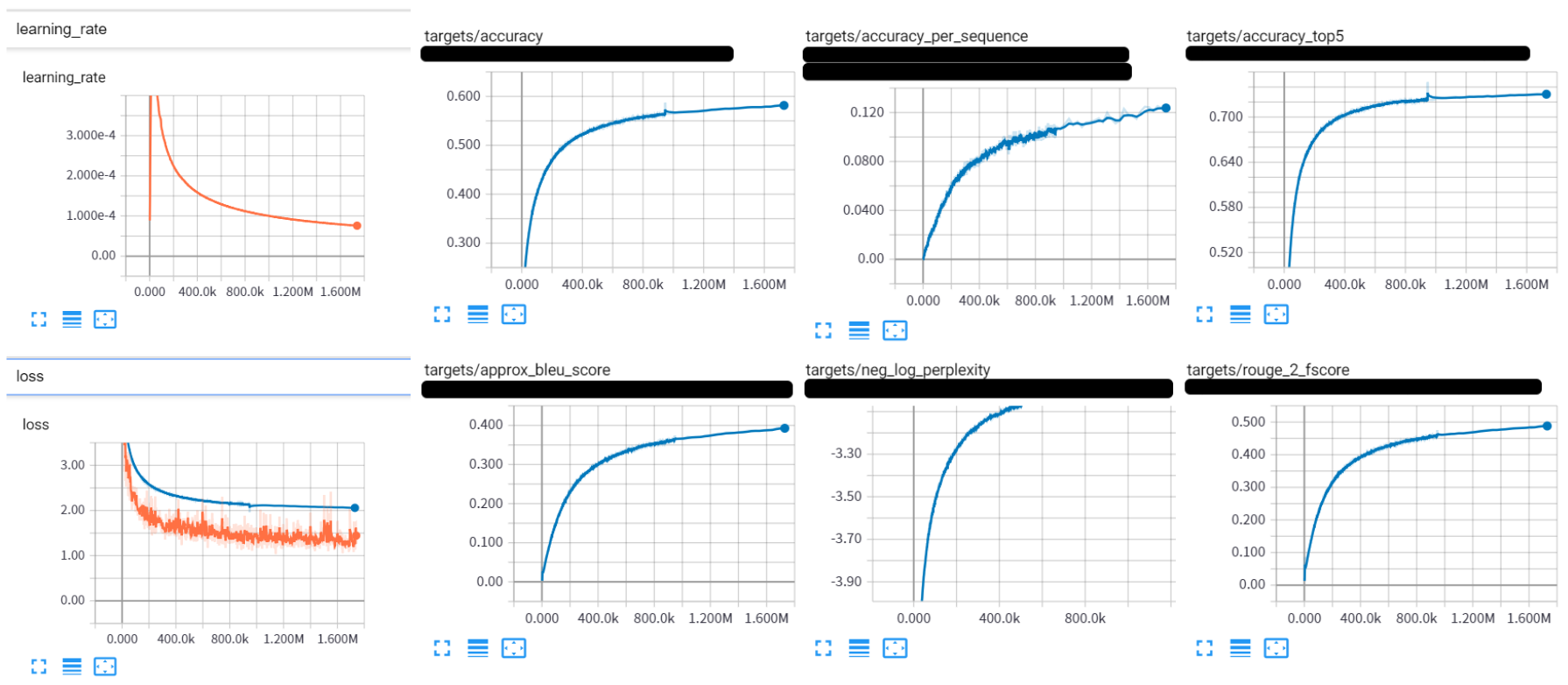
良いlearning curveだ!
学習は100万ステップもすれば十分でしょう。
デプロイ
学習が終わったら、以下のようなコマンドでモデルをエクスポート用に変換します:
t2t-exporter \
--model=transformer \
--hparams_set=<hparams_name> \
--problem=<problem_name> \
--data_dir=data \
--output_dir=output/0 \
--decode_hparams="return_beams=True,beam_size=5,alpha=0.1" \
--t2t_usr_dir=<user_dir>return_beams=Trueとすることで、beam searchの結果をスコアと一緒に返してくれます。
output/0/export以下にモデルファイルを格納したディレクトリが生成されるのでまるごとコピーしてきます。
TensorFlowで作ったNLPモデルのデプロイには、
- モデルサーバー: モデルのinputデータを受け取りoutputを返す
- クエリサーバー: テキストをモデルの入力用にベクトル化したり、モデルの出力ベクトルをテキスト化する
これら両方が必要です。前者はgoogle謹製のdockerイメージがあるのでこれを使いましょう。

後者はt2tのリポジトリではただのwhileループしかないので、flaskでサーバ化したものをdockerで動かします。これら両方をまとめたリポジトリを作りました。

docker-composeマジ神
で今回のモデルはよくできたのでgumroadで販売してみることにします。ぜひ試してみて下さい。

hubotでの利用
こちらのhubotスクリプトを使って下さい
また、hubot自体もAlpine LinuxのDockerイメージを作ってあるので軽量&簡単に立ち上げられるようになってます:
会話例
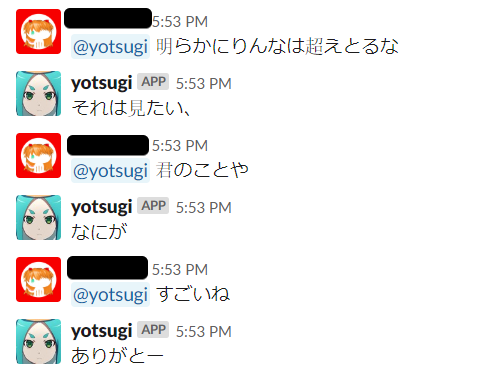
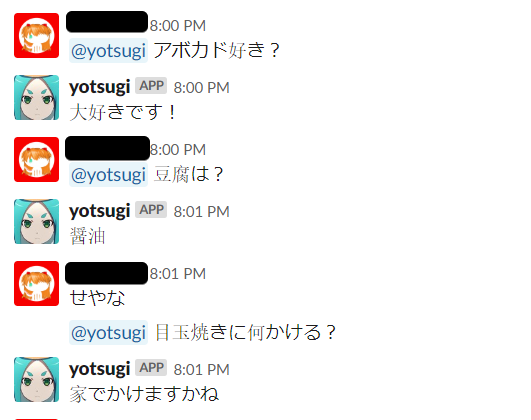
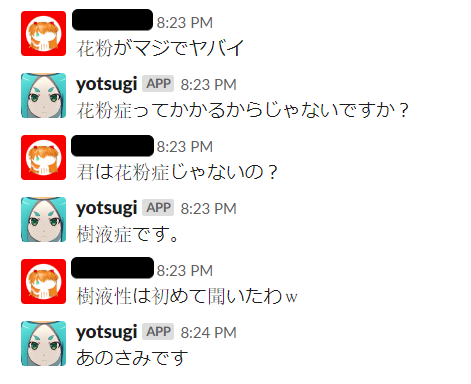
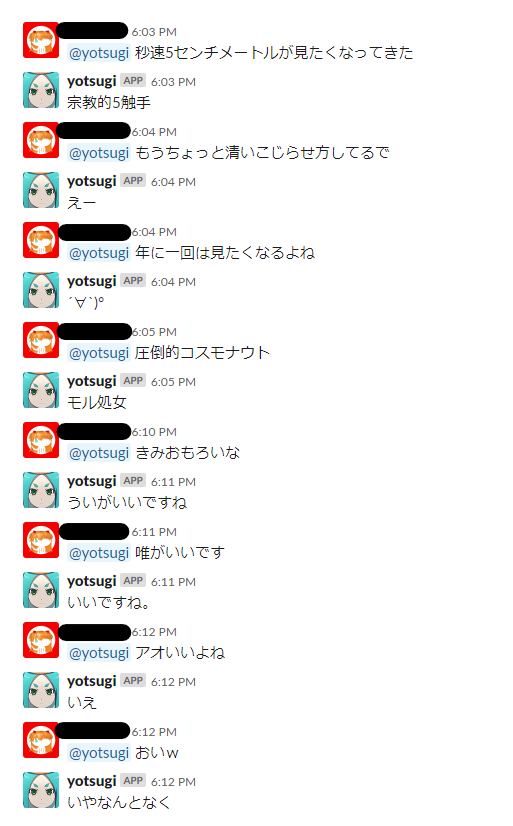
短めの文とかのよくありそうな文は特に問題ない感じで、数値とか正確さを要求するような会話はちょっと変、未知語っぽいものでもそれなりに関連した会話をしてくれるという印象です。類義語変換が思った以上に良い影響があるような気がしますね。
あぁー…いいっすねー…