
クロール&スクレイピングはweb開発者や野良データ研究者にとってはたしなみではないでしょうか。
もはや武士にとっての茶&数寄、あなたをグッと深みのある人間に見せてくれるハイソなスキルといえましょう。
しかしクローラーは大仰なものが多かったり(主にscrapinghub方面)、web側がマジでclosedになってきたりと
お茶を嗜む以前に作法を学ぶことが非常に辛くなってしまっています。本質はお茶を飲むことですらなく、そこでのコミュニケーションにあるのです。マジで。

ブラウザ動かしましょうねってことです。それも環境構築を楽に。
そういうスクリプトを書いてみました:
https://github.com/Drunkar/crawler-base
seleniumが公式のdocker imageを用意してくれているのでクソでも使えます。(知能のあるクソに限られます。)
とりあえずpythonはanacondaじゃなきゃダメな身体にされてしまっているのでanacondaを使うようにしたdockerfileとcompose.ymlを入れてます。
クローンしてきたら、
docker-compose up -dでselenium-serverのコンテナがビルドされ起動します。
- 4444ポート: selenium server
- 5900ポート: vnc sercer
です。ホストからlocalhostの4444ポートを指定してseleniumをremotewebdriverで起動すればおkです。サンプルではredditにログインして自分のフィードを取得します。auth.jsonというファイルにユーザー名とパスワードを入れ、
python crawl.py -dでクロール開始します。
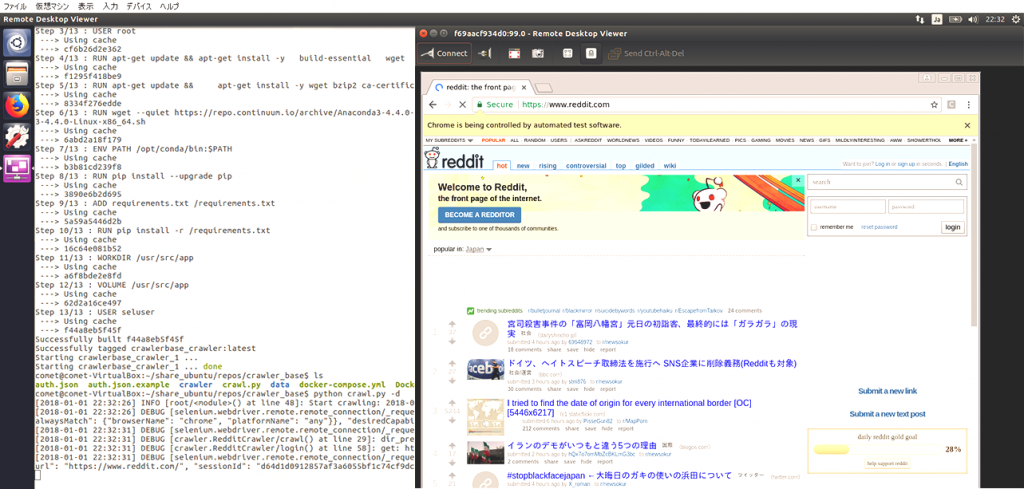
ホストpcからvncクライアントで接続すれば実際にクロールされている様子を覗くことができます。ubuntuならvinagre、macならfinder、windowsならrealvncとかがメジャーでしょうか。接続に必要なパスワードは”secret”です。
コメント